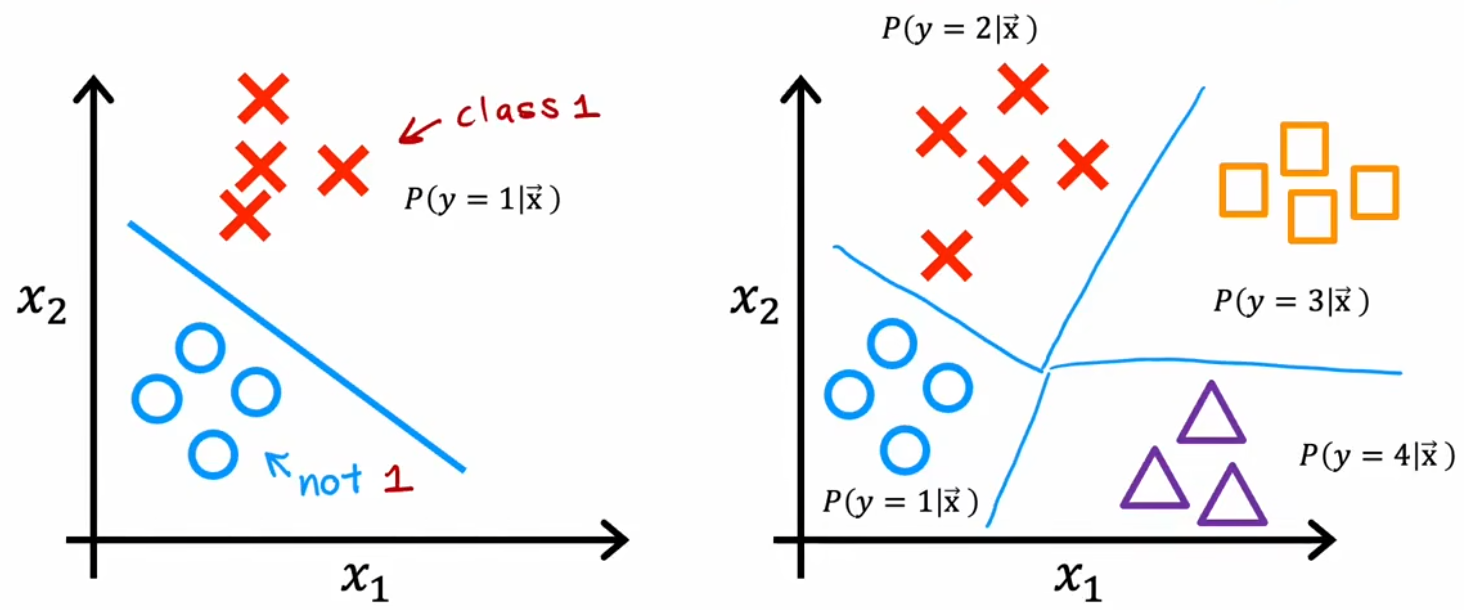
$$
\text{Loss Function: } \quad L(f(\vec{x}), y) = -y \log(f(\vec{x})) - (1 - y) \log(1 - f(\vec{x}))
\\
\text{Cost Function: } \quad
\begin{aligned}
& J(\mathbf{W}, \mathbf{B}) = \frac{1}{m} \sum_{i=1}^m L(f(\vec{x}), y), \\
& \mathbf{W} = [\mathbf{W}^{[1]}, \mathbf{W}^{[2]}, \mathbf{W}^{[3]}], \\
& \mathbf{B} = [\mathbf{\tilde{b}}^{[1]}, \mathbf{\tilde{b}}^{[2]}, \mathbf{\tilde{b}}^{[3]}].
\end{aligned}
$$
表格测试
| 激活函数 | 公式 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| Sigmoid | $ \frac{1}{1+e^{-x}} $ | 输出概率,平滑可导 | 梯度消失,非零均值 | 二分类输出层 |
| Tanh | $ \frac{e^x - e^{-x}}{e^x + e^{-x}} $ | 零均值,输出范围更大 | 梯度消失 | 隐藏层或需要中心化输出 |
| ReLU | $ \max(0, x) $ | 计算高效,缓解梯度消失 | 死亡神经元,负区间无响应 | 隐藏层(最常用) |
| Leaky ReLU | $ \max(\alpha x, x) $ | 缓解死亡神经元问题 | 需人工设置 ( \alpha ) | 深层网络隐藏层 |
| Softmax | $ \frac{e^{x_i}}{\sum_j e^{x_j}} $ | 输出概率分布 | 仅用于多分类输出层 | 多分类输出层 |