开发笔记
本期目标计划:
- Java 后端整合 Swagger + Knife4j 接口文档
- 存量用户信息导入及同步(爬虫)
- 前后端联调:搜索页面、用户信息页、用户信息修改页
- 标签内容整理
- 部分细节优化
后端整合 Swagger + Knife4j 接口文档
什么是接口文档?写接口信息的文档,每条接口包括:
- 请求参数
- 响应参数
- 错误码
- 接口地址
- 接口名称
- 请求类型
- 请求格式
- 备注
who 谁用?一般是后端或者负责人来提供,后端和前端都要使用
为什么需要接口文档?
- 有个书面内容(背书或者归档),便于大家参考和查阅,便于 沉淀和维护 ,拒绝口口相传
- 接口文档便于前端和后端开发对接,前后端联调的 介质 。后端 => 接口文档 <= 前端
- 好的接口文档支持在线调试、在线测试,可以作为工具提高我们的开发测试效率
怎么做接口文档?
- 手写(比如腾讯文档、Markdown 笔记)
- 自动化接口文档生成:自动根据项目代码生成完整的文档或在线调试的网页。Swagger,Postman(侧重接口管理)(国外);apifox、apipost、eolink(国产)
接口文档有哪些技巧?
Swagger 原理:
- 引入依赖(Swagger 或 Knife4j:https://doc.xiaominfo.com/knife4j/documentation/get_start.html)
- 自定义 Swagger 配置类
- 定义需要生成接口文档的代码位置(Controller)
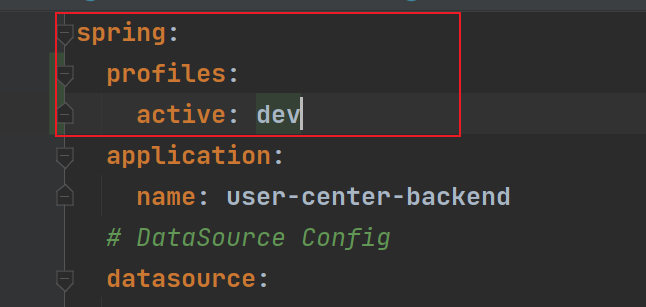
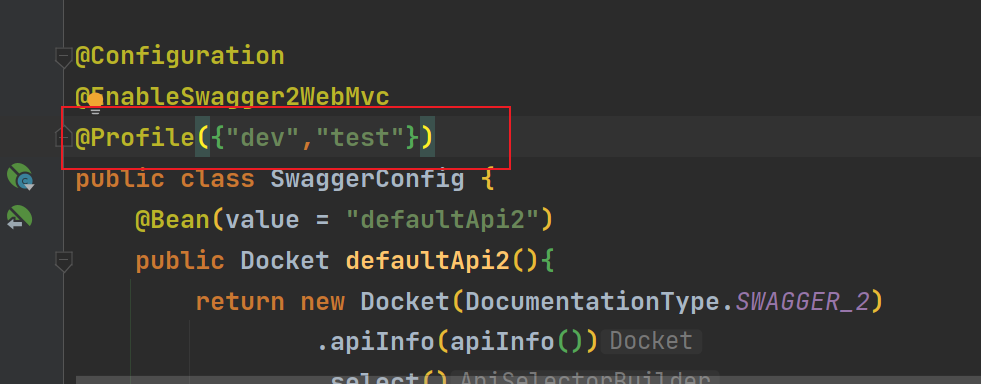
- 千万注意:线上环境不要把接口暴露出去!!!可以通过在 SwaggerConfig 配置文件开头加上
@Profile({"dev", "test"})限定配置仅在部分环境开启 - 启动即可
- 可以通过在 controller 方法上添加 [@Api、@ApiImplicitParam(name ](/Api、@ApiImplicitParam(name ) = “name”,value = “姓名”,required = true) [@ApiOperation(value ](/ApiOperation(value ) = “向客人问好”) 等注解来自定义生成的接口描述信息
如果 springboot version >= 2.6,需要添加如下配置:
spring:
mvc:
pathmatch:
matching-strategy: ANT_PATH_MATCHERtodo 怎么隐藏
存量用户信息导入及同步
- 把所有星球用户的信息导入
- 把写了自我介绍的同学的标签信息导入
FeHelper 前端辅助插件,推荐安装
看上了网页信息,怎么抓到?
- 分析原网站是怎么获取这些数据的?哪个接口?
按 F 12 打开控制台,查看网络请求,复制 curl 代码便于查看和执行:
curl "https://api.zsxq.com/v2/hashtags/48844541281228/topics?count=20" ^
-H "authority: api.zsxq.com" ^
-H "accept: application/json, text/plain, */*" ^
-H "accept-language: zh-CN,zh;q=0.9" ^
-H "cache-control: no-cache" ^
-H "origin: https://wx.zsxq.com" ^
-H "pragma: no-cache" ^
-H "referer: https://wx.zsxq.com/" ^
--compressed- 用程序去调用接口 (java okhttp httpclient / python 都可以)
- 处理(清洗)一下数据,之后就可以写到数据库里
流程
- 从 excel 中导入全量用户数据,判重 。 easy excel:https://alibaba-easyexcel.github.io/index.html
- 抓取写了自我介绍的同学信息,提取出用户昵称、用户唯一 id、自我介绍信息
- 从自我介绍中提取信息,然后写入到数据库中
EasyExcel
两种读对象的方式:
- 确定表头:建立对象,和表头形成映射关系
- 不确定表头:每一行数据映射为 Map<String, Object>
两种读取模式:
- 监听器:先创建监听器、在读取文件时绑定监听器。单独抽离处理逻辑,代码清晰易于维护;一条一条处理,适用于数据量大的场景。
- 同步读:无需创建监听器,一次性获取完整数据。方便简单,但是数据量大时会有等待时常,也可能内存溢出。
后端整合 Swagger + Knife4j
第一步:在用户中心系统的pom.xml中引入Knife4j的依赖包,Maven坐标如下:
<!--引入Knife4j的官方start包,Swagger2基于Springfox2.10.5项目-->
<dependency>
<groupId>com.github.xiaoymin</groupId>
<!--使用Swagger2-->
<artifactId>knife4j-spring-boot-starter</artifactId>
<version>2.0.9</version>
</dependency>第二步:在config目录(没有就新建)下创建Swagger配置依赖,代码如下:
@Configuration
@EnableSwagger2WebMvc
public class Knife4jConfiguration {
@Bean(value = "dockerBean")
public Docket dockerBean() {
//指定使用Swagger2规范
Docket docket=new Docket(DocumentationType.SWAGGER_2)
.apiInfo(new ApiInfoBuilder()
//描述字段支持Markdown语法
.description("# Knife4j RESTful APIs")
.termsOfServiceUrl("https://doc.xiaominfo.com/")
.contact("xiaoymin@foxmail.com")
.version("1.0")
.build())
//分组名称
.groupName("用户服务")
.select()
//这里指定Controller扫描包路径
.apis(RequestHandlerSelectors.basePackage("com.github.xiaoymin.knife4j.controller"))
.paths(PathSelectors.any())
.build();
return docket;
}
}这里鱼皮一开始使用的swagger的文档,但是由于踩坑换成了knife4j的依赖,所以创建的swagger配置格式会不大一样,我这里是按照鱼皮一开始swagger文档格式写的,整理代码如下:
package com.yupi.usercenter.config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import springfox.documentation.builders.ApiInfoBuilder;
import springfox.documentation.builders.PathSelectors;
import springfox.documentation.builders.RequestHandlerSelectors;
import springfox.documentation.service.ApiInfo;
import springfox.documentation.service.Contact;
import springfox.documentation.spi.DocumentationType;
import springfox.documentation.spring.web.plugins.Docket;
import springfox.documentation.swagger2.annotations.EnableSwagger2WebMvc;
@Configuration
@EnableSwagger2WebMvc
public class SwaggerConfig {
@Bean(value = "defaultApi2")
public Docket defaultApi2(){
return new Docket(DocumentationType.SWAGGER_2)
.apiInfo(apiInfo())
.select()
//这里一定要标注你控制器的位置
.apis(RequestHandlerSelectors.basePackage("com.yupi.usercenter.controller"))
.paths(PathSelectors.any())
.build();
}
/**
* api 信息
* @return
*/
private ApiInfo apiInfo(){
return new ApiInfoBuilder()
.title("鱼皮用户中心")
.description("鱼皮用户中心文档")
.termsOfServiceUrl("https://github.com/liyupi")
.contact(new Contact("yupi","https://github.com/liyupi","1212121@qq.com"))
.version("1.0")
.build();
}
}如果你的springboot版本是大于等于2.6以上,大概率会出现一下报错: 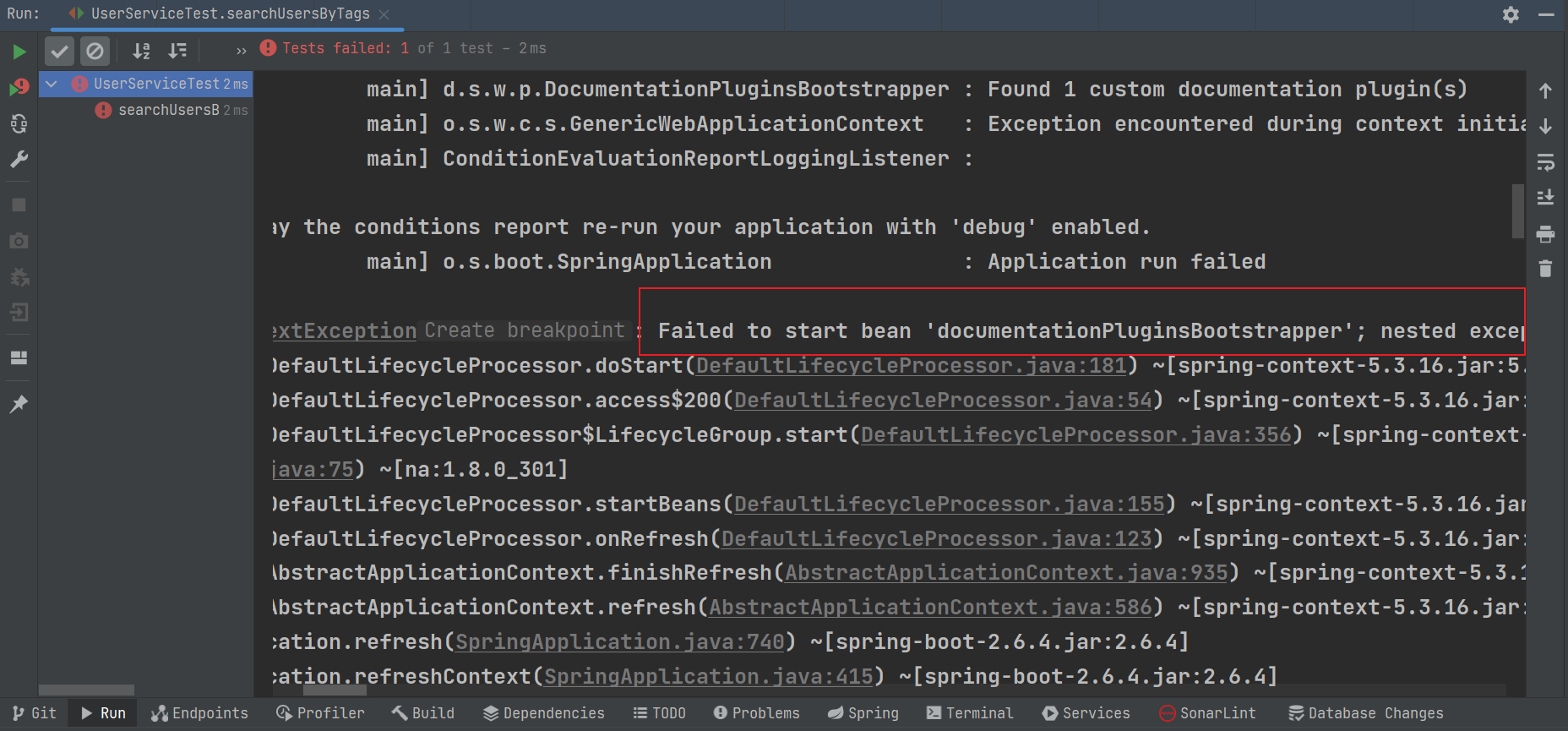 在application.yaml配置文件中添加如下配置:
在application.yaml配置文件中添加如下配置:
spring:
mvc:
pathmatch:
matching-strategy: ANT_PATH_MATCHER访问这个路径:http://localhost:8080/api/doc.html 显示如下 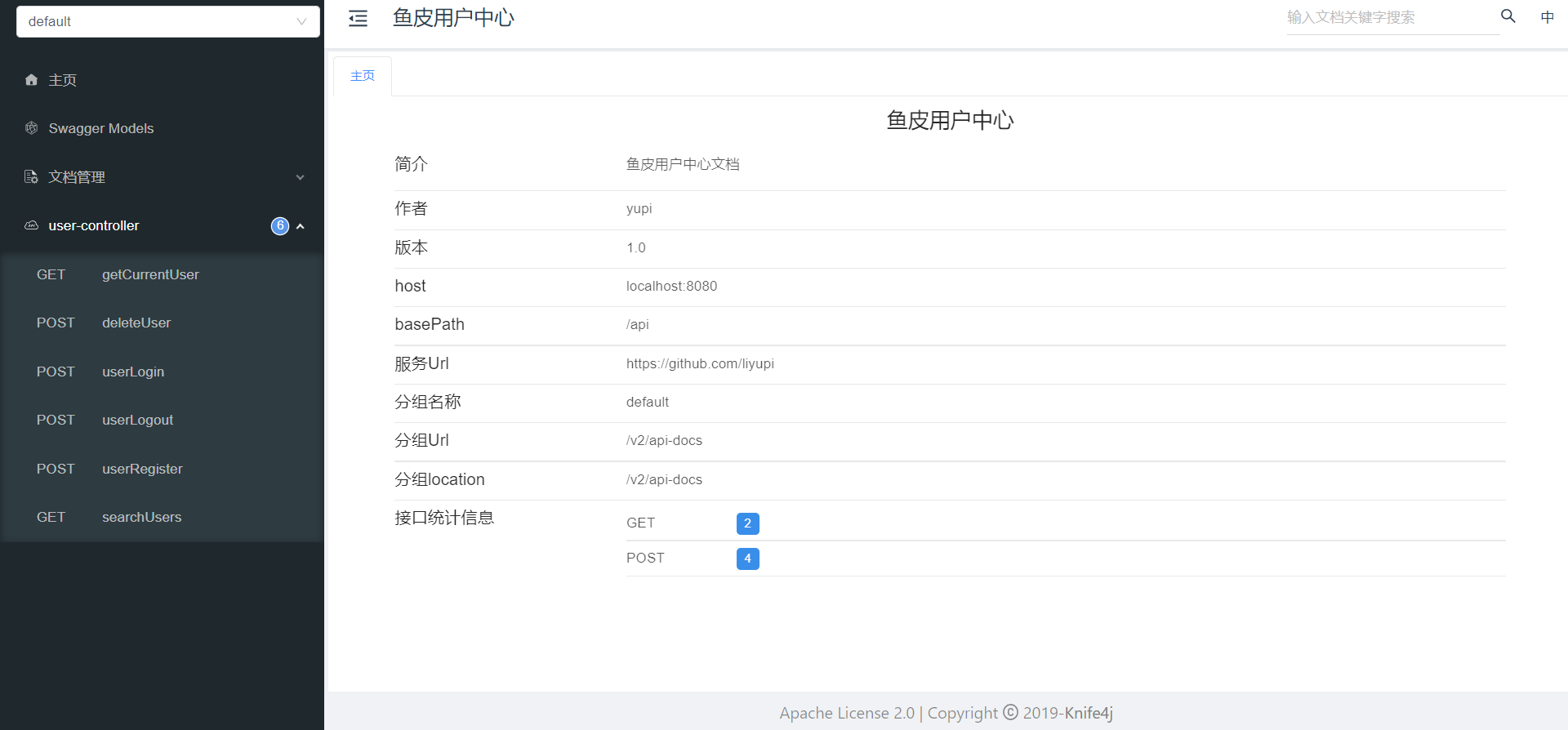
第三步:测试knife4j
首先需要登录 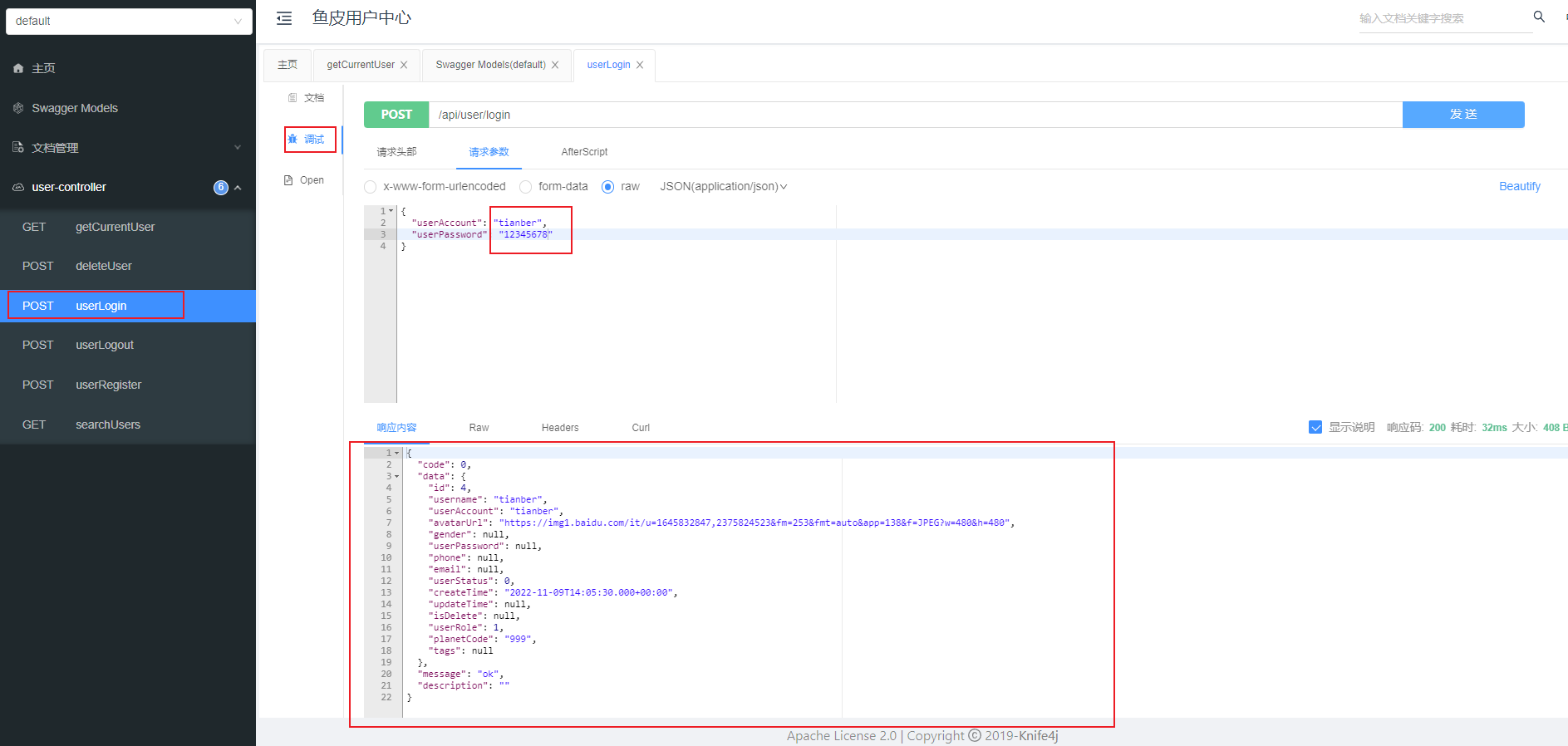 成功获取响应内容 现在再测试下获取登录用户信息
成功获取响应内容 现在再测试下获取登录用户信息 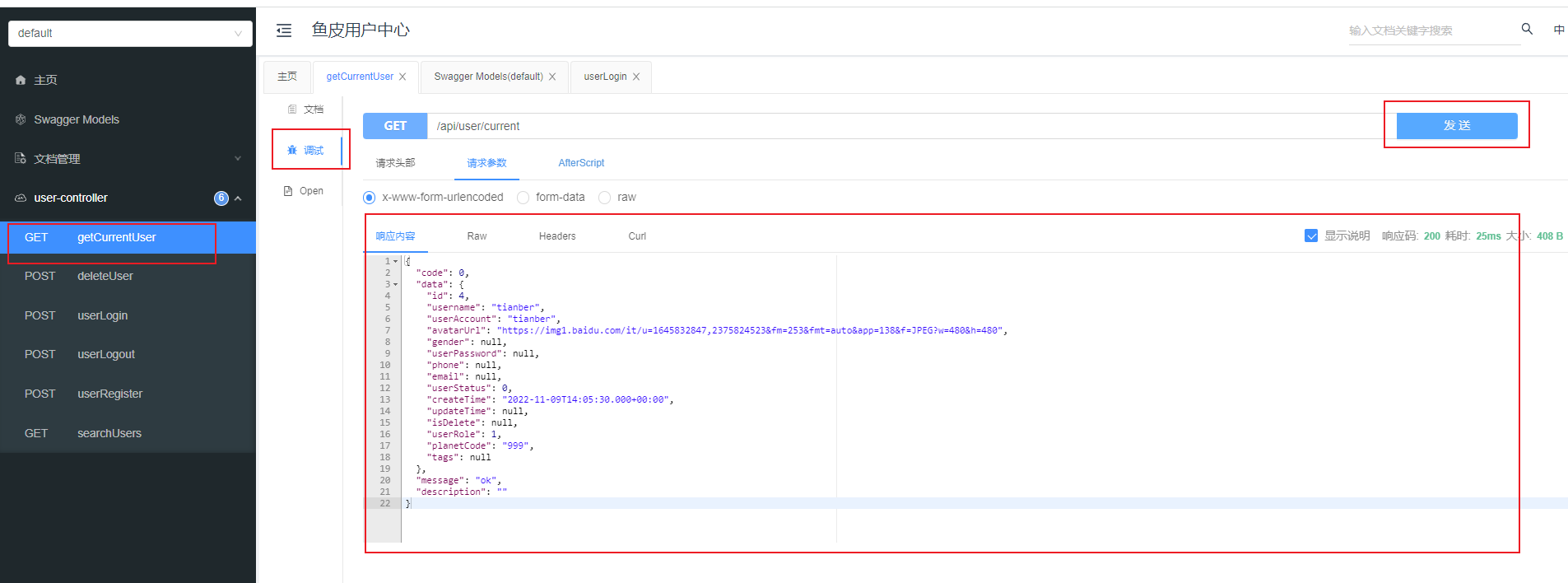 可以通过在 controller 方法上添加 @Api、@ApiImplicitParam(name = “name”,value = “姓名”,required = true) @ApiOperation(value = “向客人问好”) 等注解来自定义生成的接口描述信息 这里就不演示了看个人需求
可以通过在 controller 方法上添加 @Api、@ApiImplicitParam(name = “name”,value = “姓名”,required = true) @ApiOperation(value = “向客人问好”) 等注解来自定义生成的接口描述信息 这里就不演示了看个人需求
存量用户信息导入及同步
第一步:分析原网站是怎么获取这些数据的?哪个接口?
- 按 F12 打开控 制台,查看网络请求,复制 curl 代码便于查看和执行:
curl "https://api.zsxq.com/v2/hashtags/48844541281228/topics?count=20" ^
-H "authority: api.zsxq.com" ^
-H "accept: application/json, text/plain, */*" ^
-H "accept-language: zh-CN,zh;q=0.9" ^
-H "cache-control: no-cache" ^
-H "origin: https://wx.zsxq.com" ^
-H "pragma: no-cache" ^
-H "referer: https://wx.zsxq.com/" ^
--compressed- 用程序去调用接口 (java okhttp httpclient / python 都可以)
- 处理(清洗)一下数据,之后就可以写到数据库里
第二步:具体实现流程
1.从 excel 中导入全量用户数据,判重 这里使用了easyexcel 官网: 在pom.xml里引入依赖
<!-- https://mvnrepository.com/artifact/com.alibaba/easyexcel -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>easyexcel</artifactId>
<version>3.1.1</version>
</dependency>现在开始写读表格的程序 首先这是一次性的代码,我们先创建一个once目录,再创建XingQiuTableUserInfo.java文件,这个文件作用就是将表格和对象相关联起来
package com.yupi.usercenter.once;
import com.alibaba.excel.annotation.ExcelProperty;
import lombok.Data;
/**
* 星球表格用户信息
*/
@Data
public class XingQiuTableUserInfo {
/**
* 星球编号
*/
@ExcelProperty("成员编号")
private String planetCode;
/**
* 用户昵称
*/
@ExcelProperty("成员昵称")
private String userName;
}创建一个监听器
package com.yupi.usercenter.once;
import com.alibaba.excel.context.AnalysisContext;
import com.alibaba.excel.read.listener.ReadListener;
import lombok.extern.slf4j.Slf4j;
@Slf4j
public class TableListener implements ReadListener<XingQiuTableUserInfo> {
/**
* 这个每一条数据解析都会来调用
*
* @param data one row value. Is is same as {@link AnalysisContext#readRowHolder()}
* @param context
*/
@Override
public void invoke(XingQiuTableUserInfo data, AnalysisContext context) {
System.out.println(data);
}
/**
* 所有数据解析完成了 都会来调用
*
* @param context
*/
@Override
public void doAfterAllAnalysed(AnalysisContext context) {
System.out.println("已解析完成");
}
}最后我们要使用,先创建一个ImportExcel类作为实现类,先使用官方文档的方法一。即第一种读取方式:监听器:先创建监听器、在读取文件时绑定监听器。单独抽离处理逻辑,代码清晰易于维护;一条一条处理,适用于数据量大的场景。 同时我们也需要创建一个假数据的excel表格来进行测试,我这边提供一个自己写的 假数据:testExcel.xlsx
package com.yupi.usercenter.once;
import com.alibaba.excel.EasyExcel;
/**
* 导入Excel
*/
public class ImportExcel {
public static void main(String[] args) {
//写法1
String fileName = "F:\\code\\星球项目\\用户中心\\user-center-backend-master\\src\\main\\resources\\testExcel.xlsx";
// 这里 需要指定读用哪个class去读,然后读取第一个sheet 文件流会自动关闭
// 这里每次会读取100条数据 然后返回过来 直接调用使用数据就行
EasyExcel.read(fileName,XingQiuTableUserInfo.class,new TableListener()).sheet().doRead();
}
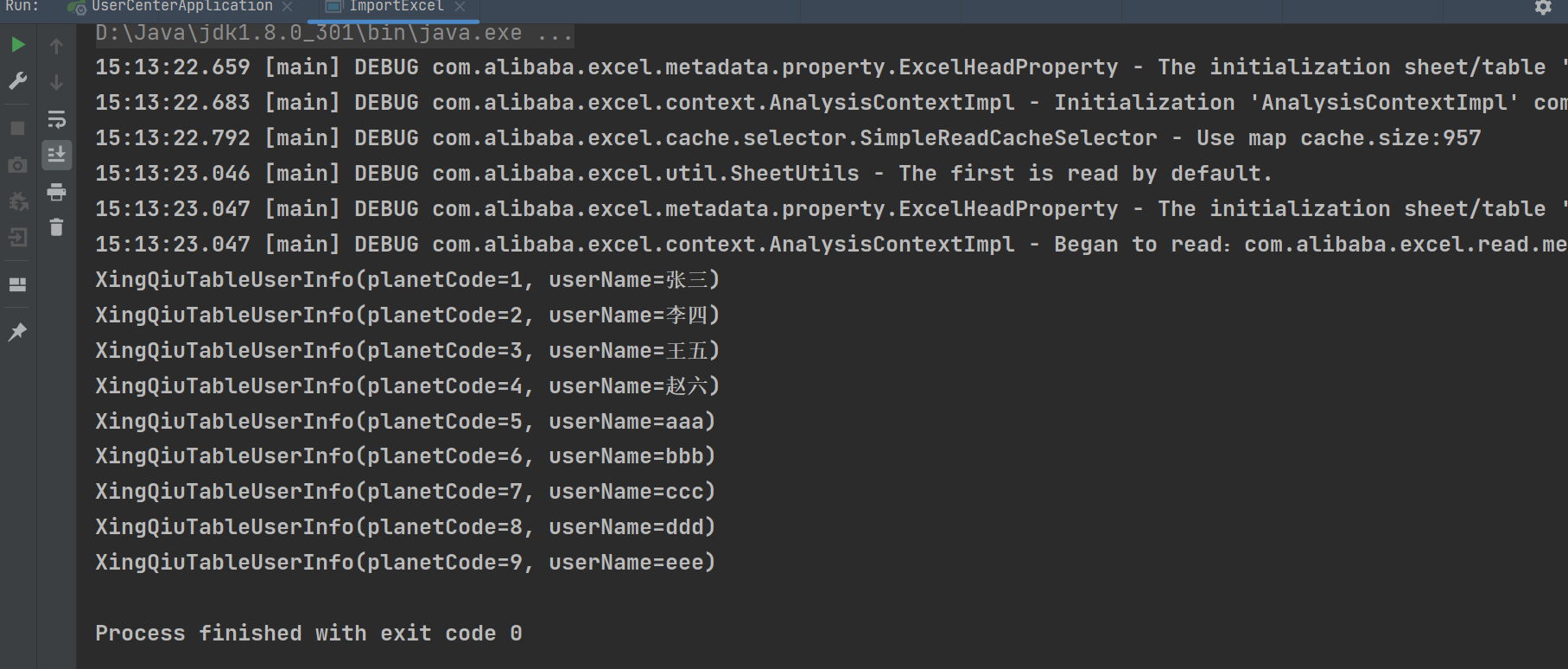
}测试运行 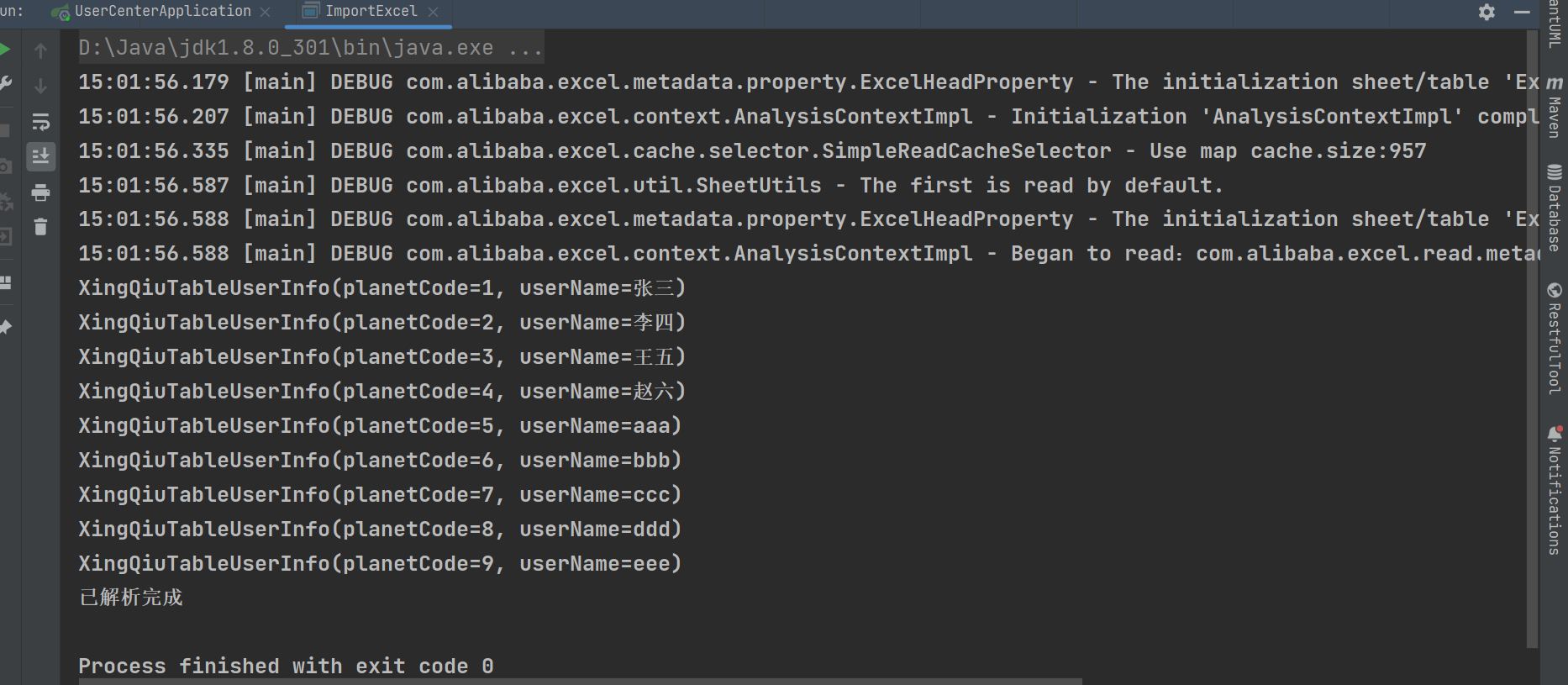 试一下第二种方法:同步读:无需创建监听器,一次性获取完整数据。方便简单,但是数据量大时会有等待时常,也可能内存溢出。在ImportExcel里创建两个方法,为了以后调用方便,修改代码如下
试一下第二种方法:同步读:无需创建监听器,一次性获取完整数据。方便简单,但是数据量大时会有等待时常,也可能内存溢出。在ImportExcel里创建两个方法,为了以后调用方便,修改代码如下
package com.yupi.usercenter.once;
import com.alibaba.excel.EasyExcel;
import java.util.List;
/**
* 导入Excel
*/
public class ImportExcel {
public static void main(String[] args) {
String fileName = "F:\\\\code\\\\星球项目\\\\用户中心\\\\user-center-backend-master\\\\src\\\\main\\\\resources\\\\testExcel.xlsx";
// listenerRead(fileName);
synchronousRead(fileName);
}
/**
* 监听器读
* @param fileName
*/
public static void listenerRead(String fileName) {
// 这里 需要指定读用哪个class去读,然后读取第一个sheet 文件流会自动关闭
// 这里每次会读取100条数据 然后返回过来 直接调用使用数据就行
EasyExcel.read(fileName, XingQiuTableUserInfo.class, new TableListener()).sheet().doRead();
}
/**
* 同步读
* @param fileName
*/
public static void synchronousRead(String fileName) {
// 这里 需要指定读用哪个class去读,然后读取第一个sheet 同步读取会自动finish
List<XingQiuTableUserInfo> list = EasyExcel.read(fileName).head(XingQiuTableUserInfo.class).sheet().doReadSync();
for (XingQiuTableUserInfo data : list) {
System.out.println(data);
}
}
} 千万注意:线上环境不要把接口暴露出去!!!可以通过在 SwaggerConfig 配置文件开头加上 @Profile({“dev”, “test”}) 限定配置仅在部分环境开启 先配置为prod,再运行,发现访问失败
千万注意:线上环境不要把接口暴露出去!!!可以通过在 SwaggerConfig 配置文件开头加上 @Profile({“dev”, “test”}) 限定配置仅在部分环境开启 先配置为prod,再运行,发现访问失败  去application.yml中修改默认配置,并在swaggerConfig中加上@Profile注解
去application.yml中修改默认配置,并在swaggerConfig中加上@Profile注解