开发笔记
介绍:帮助大家找到志同道合的伙伴,移动端 H5 网页(尽量兼容 PC 端)
需求分析
- 用户去添加标签,标签的分类(要有哪些标签、怎么把标签进行分类)学习方向 java / c++,工作 / 大学
- 主动搜索:允许用户根据标签去搜索其他用户
- Redis 缓存
- 组队
- 创建队伍
- 加入队伍
- 根据标签查询队伍
- 邀请其他人
- 允许用户去修改标签
- 推荐
- 相似度计算算法 + 本地分布式计算
技术栈
前端
- Vue 3 开发框架(提高页面开发的效率)
- Vant UI(基于 Vue 的移动端组件库)(React 版 Zent)
- Vite 2(打包工具,快!)
- Nginx 来单机部署
后端
- Java 编程语言 + SpringBoot 框架
- SpringMVC + MyBatis + MyBatis Plus(提高开发效率)
- MySQL 数据库
- Redis 缓存
- Swagger + Knife4j 接口文档
第一期计划
- 前端项目初始化 15 min
- 前端主页 + 组件概览 15 min
- 数据库表设计 15 min
- 标签表
- 用户表
- 初始化后端项目
- 开发后端 - 根据标签搜索用户 30 min
- 开发前端 - 根据标签搜索用户 20 min
项目开始
一、前端项目初始化
用脚手架初始化项目
- Vue CLI https://cli.vuejs.org/zh/
- Vite 脚手架 :https://vitejs.cn/guide/#scaffolding-your-first-vite-project
整合组件库 Vant:
- 安装 Vant
- 按需引入 npm i vite-plugin-style-import@1.4.1 -D
开发页面经验:
1. 多参考
2. 从整体到局部
3. 先想清楚页面要做成什么样子,再写代码1.在需要创建项目的目录输入cmd来初始化搭建项目
yarn create vite第一个输入项目的名称 第二个选择脚手架类型 ——vue 第三个选择语言 ——ts 初始化总截图 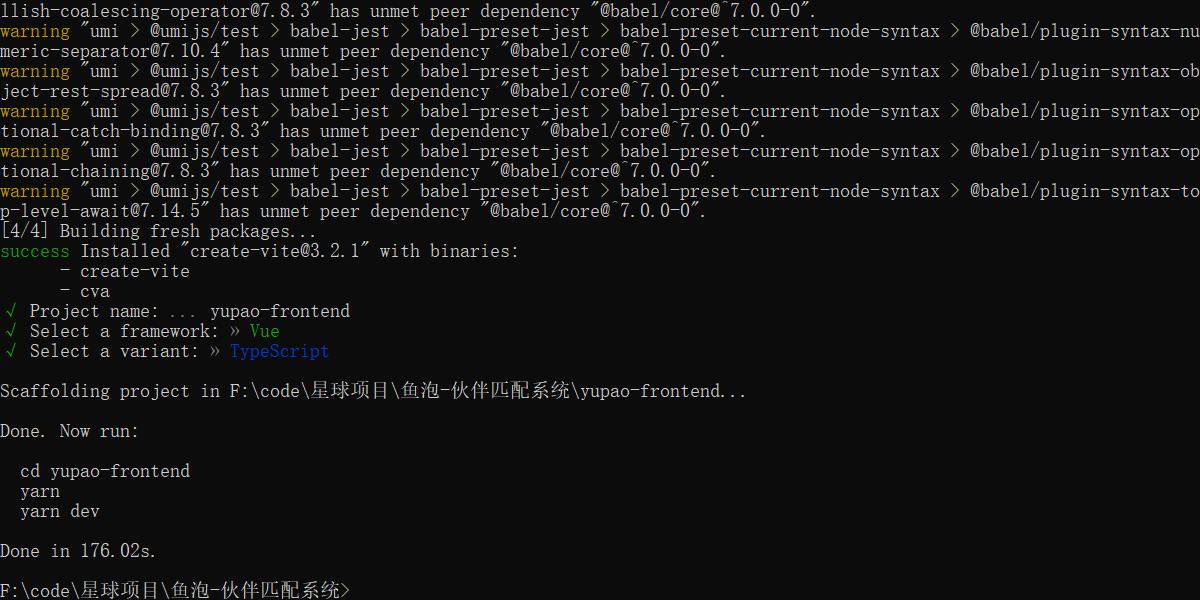
2.初始化完善
用webstorm或者vscode打开刚创建的项目(这里我选择了webstorm) (1).首先在终端中输入yarn或者npm install导入依赖 (2).在package.json中点击dev启动 我这边发现端口不是3000,为了后续方便,可以修改vite.config.ts文件 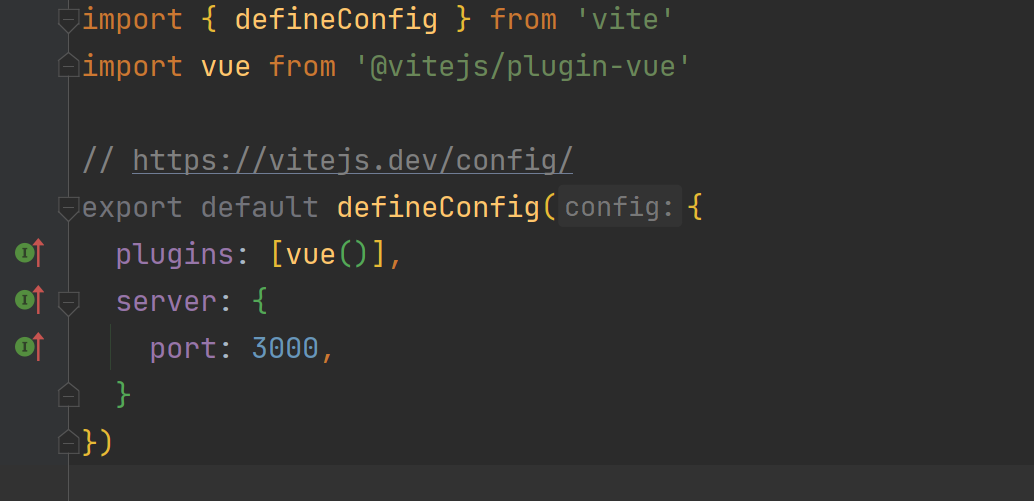 又发现打开的网页界面也不一致(算了,走一步是一步)
又发现打开的网页界面也不一致(算了,走一步是一步)  (3).整合组件库
(3).整合组件库
# 通过 npm 安装
npm i vite-plugin-style-import@1.4.1 -D
# 通过 yarn 安装
yarn add vite-plugin-style-import@1.4.1 -D这里推荐npm方式,yarn大概率会像鱼皮那样报错,安装失败 安装完成后,在 vite.config.js 文件中配置插件:
import vue from '@vitejs/plugin-vue';
import styleImport, { VantResolve } from 'vite-plugin-style-import';
export default {
plugins: [
vue(),
styleImport({
resolves: [VantResolve()],
}),
],
};整理如下:
import { defineConfig } from 'vite'
import vue from '@vitejs/plugin-vue'
import styleImport, { VantResolve } from 'vite-plugin-style-import';
// https://vitejs.dev/config/
export default defineConfig({
plugins: [
vue(),
styleImport({
resolves: [VantResolve()],
}),
]
server: {
port: 3000,
}
})通过npm安装vant
# Vue 3 项目,安装最新版 Vant
npm i vant接着引入组件在main.ts文件里
import { createApp } from 'vue';
import { Button } from 'vant';
const app = createApp();
app.use(Button);整理如下
import { createApp } from 'vue'
import './style.css'
import App from './App.vue'
import { Button } from 'vant';
const app = createApp(App);
app.use(Button);
app.mount('#app');现在可以测试一下引入是否成功
<van-button type="primary">主要按钮</van-button>
<van-button type="success">成功按钮</van-button>
<van-button type="default">默认按钮</van-button>
<van-button type="warning">警告按钮</van-button>
<van-button type="danger">危险按钮</van-button>黏贴到App.vue里面
<template>
<div>
<a href="https://vitejs.dev" target="_blank">
<img src="/vite.svg" class="logo" alt="Vite logo" />
</a>
<a href="https://vuejs.org/" target="_blank">
<img src="./assets/vue.svg" class="logo vue" alt="Vue logo" />
</a>
</div>
<HelloWorld msg="Vite + Vue" />
<van-button type="primary">主要按钮</van-button>
<van-button type="success">成功按钮</van-button>
<van-button type="default">默认按钮</van-button>
<van-button type="warning">警告按钮</van-button>
<van-button type="danger">危险按钮</van-button>
</template>运行,启动项目访问,我这里出现了报错 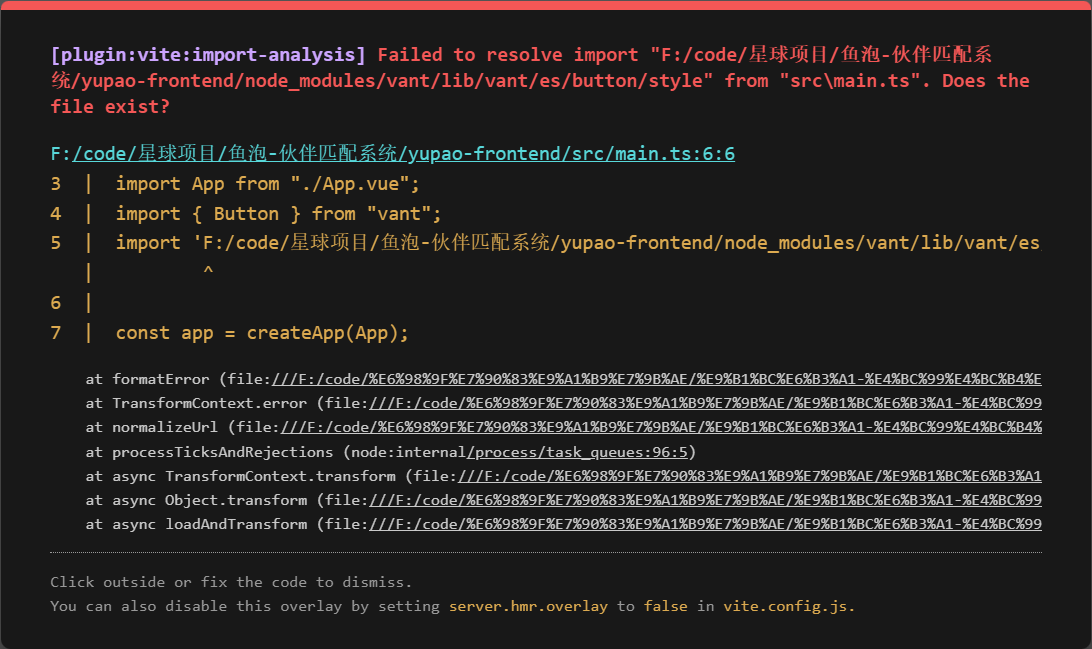 发现是依赖引入路径的问题,百度! 修改vite.config.ts代码,增加如下代码
发现是依赖引入路径的问题,百度! 修改vite.config.ts代码,增加如下代码
export default defineConfig({
plugins: [
vue(),
styleImport({
resolves: [VantResolve()],
//增加的代码
libs: [
{
libraryName: 'vant',
esModule: true,
resolveStyle: name => `../es/${name}/style`
}
]
}),
],
server: {
port: 3000,
}
})再次启动项目,不报错,在底部成功出现了按键 
二、前端主页 + 组件概览
设计: 导航条:展示当前页面名称 主页搜索框 => 搜索页 => 搜索结果页(标签筛选页) 内容 tab 栏:
- 主页(推荐页 + 广告 )
- 搜索框
- banner
- 推荐信息流
- 队伍页
- 用户页(消息 - 暂时考虑发邮件)
开发: 很多页面要复用组件 / 样式,重复写很麻烦、不利于维护,所以抽象一个通用的布局(Layout) 组件化
1. 删除App.vue中无用的代码,只剩下框架;删除components中的hello文件,建立layouts文件夹(复用,通用布局)
2.搭建基本框架
复制navbar模块的代码如下,插入到layouts目录下的BasicLayouts.vue文件中
<van-nav-bar
title="标题"
left-text="返回"
right-text="按钮"
left-arrow
@click-left="onClickLeft"
@click-right="onClickRight"
/>
import { Toast } from 'vant';
export default {
setup() {
const onClickLeft = () => history.back();
const onClickRight = () => Toast('按钮');
return {
onClickLeft,
onClickRight,
};
},
};
<van-nav-bar title="标题" left-text="返回" left-arrow>
<template #right>
<van-icon name="search" size="18" />
</template>
</van-nav-bar>整理可得
<template>
<van-nav-bar
title="标题"
left-arrow
@click-left="onClickLeft"
@click-right="onClickRight"
>
<template #right>
<van-icon name="search" size="18" />
</template>
</van-nav-bar>
</template>
<script setup>
const onClickLeft = () => alert('左');
const onClickRight = () => alert('右');
</script>
<style scoped>
</style>在其中<script setup>中的setup是把下面的常量暴露出去 同时不要忘了在main.ts中按需引入组件
import {Button, Icon, NavBar} from 'vant';
app.use(NavBar);
app.use(Icon);最后再App.vue中引入组件
<script setup lang="ts">
import BasicLayout from "./components/layouts/BasicLayout.vue";
</script>
<template>
<BasicLayout />
</template>结果显示如下 
 根据需求进行魔改(如法炮制): 引入底部的tabbar 复制如下的代码到BasicLayouts.vue中
根据需求进行魔改(如法炮制): 引入底部的tabbar 复制如下的代码到BasicLayouts.vue中
<van-tabbar v-model="active" @change="onChange">
<van-tabbar-item icon="home-o">标签 1</van-tabbar-item>
<van-tabbar-item icon="search">标签 2</van-tabbar-item>
<van-tabbar-item icon="friends-o">标签 3</van-tabbar-item>
<van-tabbar-item icon="setting-o">标签 4</van-tabbar-item>
</van-tabbar>
import { ref } from 'vue';
import { Toast } from 'vant';
export default {
setup() {
const active = ref(0);
const onChange = (index) => Toast(`标签 ${index}`);
return {
icon,
onChange,
};
},
};整理如下
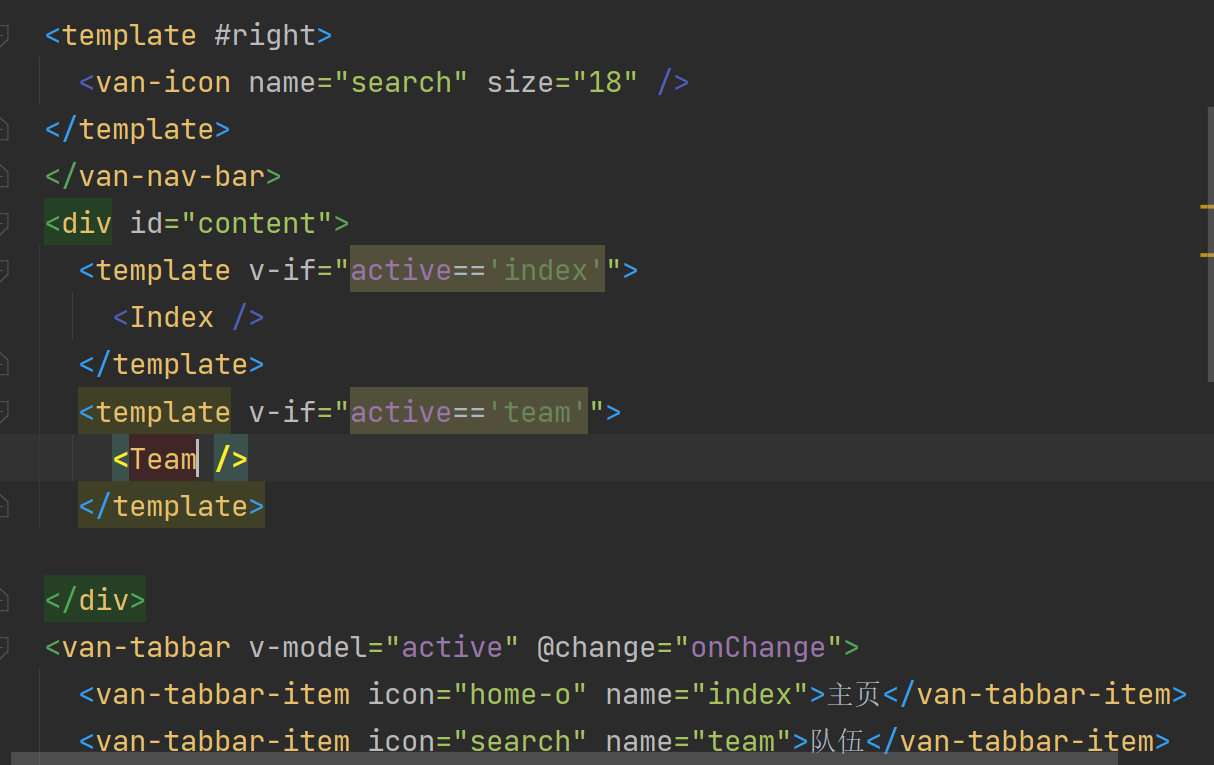
<template>
<van-tabbar v-model="active" @change="onChange">
<van-tabbar-item icon="home-o" name="index">主页</van-tabbar-item>
<van-tabbar-item icon="search" name="team">队伍</van-tabbar-item>
<van-tabbar-item icon="friends-o" name="user">个人</van-tabbar-item>
</van-tabbar>
</template>
<script setup>
import { ref } from 'vue';
import { Toast } from 'vant';
const active = ref("index");
const onChange = (index) => Toast(`标签 ${index}`);
</script>同时这个也需要在main.ts中引入组件
import {Button, Icon, NavBar, Tabbar, TabbarItem} from 'vant';
app.use(Tabbar);
app.use(TabbarItem);const active = ref(“index”); 这句的作用是在进入页面时默认index页面的图标是高亮的 通过change事件来监听选中标签的变化  注意:其中一定要把main.ts中的import ‘./style.css’删去,我这边初始化的文件里有这一行,否则会引起样式冲突。
注意:其中一定要把main.ts中的import ‘./style.css’删去,我这边初始化的文件里有这一行,否则会引起样式冲突。
3.完善,引入两个页面,创建pages目录和index.vue和team.vue,并在BasicLayouts.vue中引入
 结果如下
结果如下 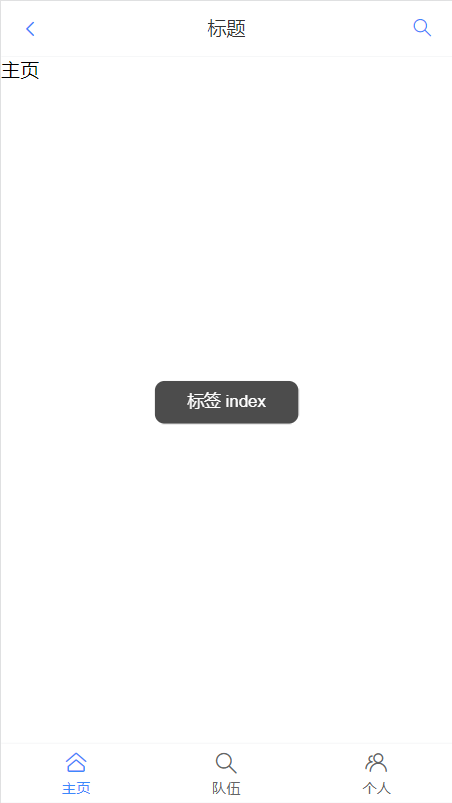
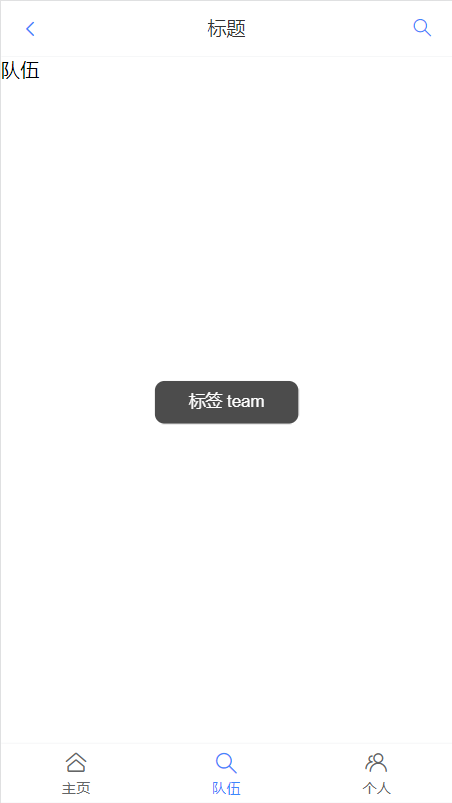 前端主页+组件到此完成
前端主页+组件到此完成
三、数据库表设计
标签的分类(要有哪些标签、怎么把标签进行分类) 新增标签表(分类表) 建议用标签,不要用分类,更灵活。 性别:男、女 方向:Java、C++、Go、前端 正在学:Spring 目标:考研、春招、秋招、社招、考公、竞赛(蓝桥杯)、转行、跳槽 段位:初级、中级、高级、王者 身份:小学、初中、高中、大一、大二、大三、大四、学生、待业、已就业、研一、研二、研三 状态:乐观、有点丧、一般、单身、已婚、有对象 【用户自己定义标签】? 字段: id int 主键 标签名 varchar 非空(必须唯一,唯一索引) 上传标签的用户 userId int(如果要根据 userId 查已上传标签的话,最好加上,普通索引) 父标签 id ,parentId,int(分类) 是否为父标签 isParent, tinyint(0 不是父标签、1 - 父标签) 创建时间 createTime,datetime 更新时间 updateTime,datetime 是否删除 isDelete, tinyint(0、1)
怎么查询所有标签,并且把标签分好组?按父标签 id 分组,能实现 √ 根据父标签查询子标签?根据 id 查询,能实现 √
SQL 语言分类: DDL define 建表、操作表 DML manage 更新删除数据,影响实际表里的内容 DCL control 控制,权限 DQL query 查询,select https://www.cnblogs.com/fan-yuan/p/7879353.html
修改用户表 用户有哪些标签? 根据自己的实际需求来!!! 此处选择第一种
- 直接在用户表补充 tags 字段,[‘Java’, ‘男’] 存 json 字符串 优点:查询方便、不用新建关联表,标签是用户的固有属性(除了该系统、其他系统可能要用到,标签是用户的固有属性)节省开发成本 查询用户列表,查关系表拿到这 100 个用户有的所有标签 id,再根据标签 id 去查标签表。 哪怕性能低,可以用缓存。 缺点:用户表多一列,会有点
- 加一个关联表,记录用户和标签的关系 关联表的应用场景:查询灵活,可以正查反查 缺点:要多建一个表、多维护一个表 重点:企业大项目开发中尽量减少关联查询,很影响扩展性,而且会影响查询性能
1.新建标签表
ddl语句如下
-- auto-generated definition
create table tag
(
id bigint auto_increment comment 'id' primary key,
tagName varchar(256) null comment '标签名称',
userId bigint null comment '用户id',
parentId bigint null comment '父标签id',
isParent tinyint null comment '0-不是父标签,1-是父标签',
createTime datetime default CURRENT_TIMESTAMP null comment '创建时间',
updateTime datetime default CURRENT_TIMESTAMP null on update CURRENT_TIMESTAMP comment '更新时间',
isDelete tinyint default 0 not null comment '是否删除'
)
comment '标签表';2.更新用户表
在原先的user表的ddl中添加下面这句并运行
alter table user add COLUMN tags varchar(1024) null comment '标签列表';然后为标签名和上传标签的用户添加索引,其中标签名是唯一索引,这是为了以后利用标签名搜索 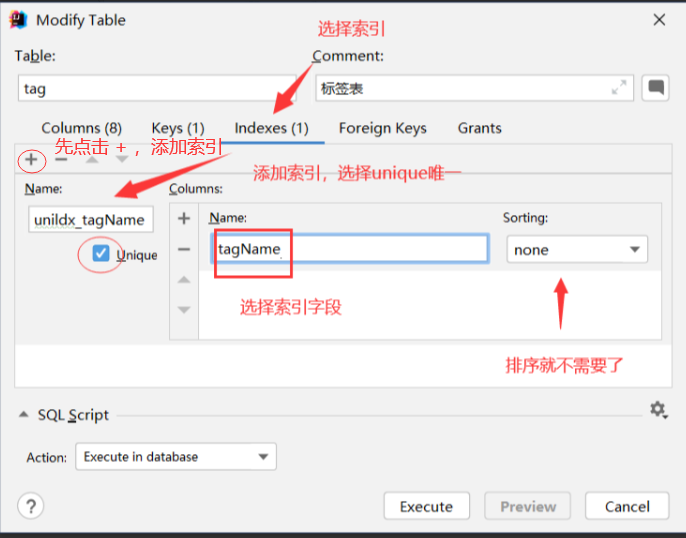
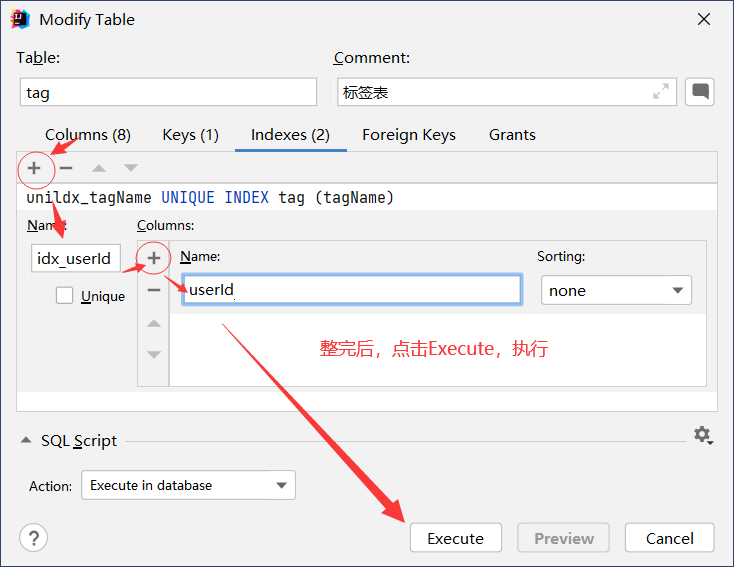 最后把增加字段的语句和标签表的语句写入到create_table.sql中,到此数据库表设计完成
最后把增加字段的语句和标签表的语句写入到create_table.sql中,到此数据库表设计完成
四、开发后端接口
1.搜索标签
- 允许用户传入多个标签,多个标签都存在才搜索出来 and。like ‘%Java%’ and like ‘%C++%’。
- 允许用户传入多个标签,有任何一个标签存在就能搜索出来 or。like ‘%Java%’ or like ‘%C++%’
两种方式:
- SQL 查询(实现简单,可以通过拆分查询进一步优化)
- 内存查询(灵活,可以通过并发进一步优化)
- 如果参数可以分析,根据用户的参数去选择查询方式,比如标签数
- 如果参数不可分析,并且数据库连接足够、内存空间足够,可以并发同时查询,谁先返回用谁。
- 还可以 SQL 查询与内存计算相结合,比如先用 SQL 过滤掉部分 tag
建议通过实际测试来分析哪种查询比较快,数据量大的时候验证效果更明显!
2.解析 JSON 字符串
序列化:java对象转成 json 反序列化:把 json 转为 java 对象 java json 序列化库有很多:
- gson(google 的)
- fastjson alibaba(ali 出品,快,但是漏洞太多)
- jackson
- kryo
五、初始化后端项目
查询带有标签用户的数量时,利用到user表,所以在用户中心项目编写代码 用户中心来集中提供用户的检索、操作、注册、登录、鉴权
1.删除target目录
2.在UserServiceImpl中创建searchUsersByTags方法,并在上面添加@Override,把此方法写入到UserService中
下图为具体的searchUsersByTags
/**
* 根据标签搜索用户
*
* @param tagNameList 用户拥有的标签
* @return
*/
@Override
public List<User> searchUsersByTags(List<String> tagNameList){
if (CollectionUtils.isEmpty(tagNameList)){
throw new BusinessException(ErrorCode.PARAMS_ERROR);
}
//拼接 and 查询
//like '%Java%' and like '%Python%'
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
for(String tagName : tagNameList){
queryWrapper=queryWrapper.like("tags",tagName);
}
List<User> userList = userMapper.selectList(queryWrapper);
return userList.stream().map(this::getSafetyUser).collect(Collectors.toList());
}3.对searchUsersByTags方法进行测试
进入到UserServiceTest中,编写方法去测试
@Test
public void searchUsersByTags(){
List<String> tagNameList = Arrays.asList("java", "python");
List<User> userList = userService.searchUsersByTags(tagNameList);
Assert.assertNotNull(userList);
}此时的userMapper.xml,脱敏方法以及user类中并未及时更新,缺少了tags字段,所以现在进行添加 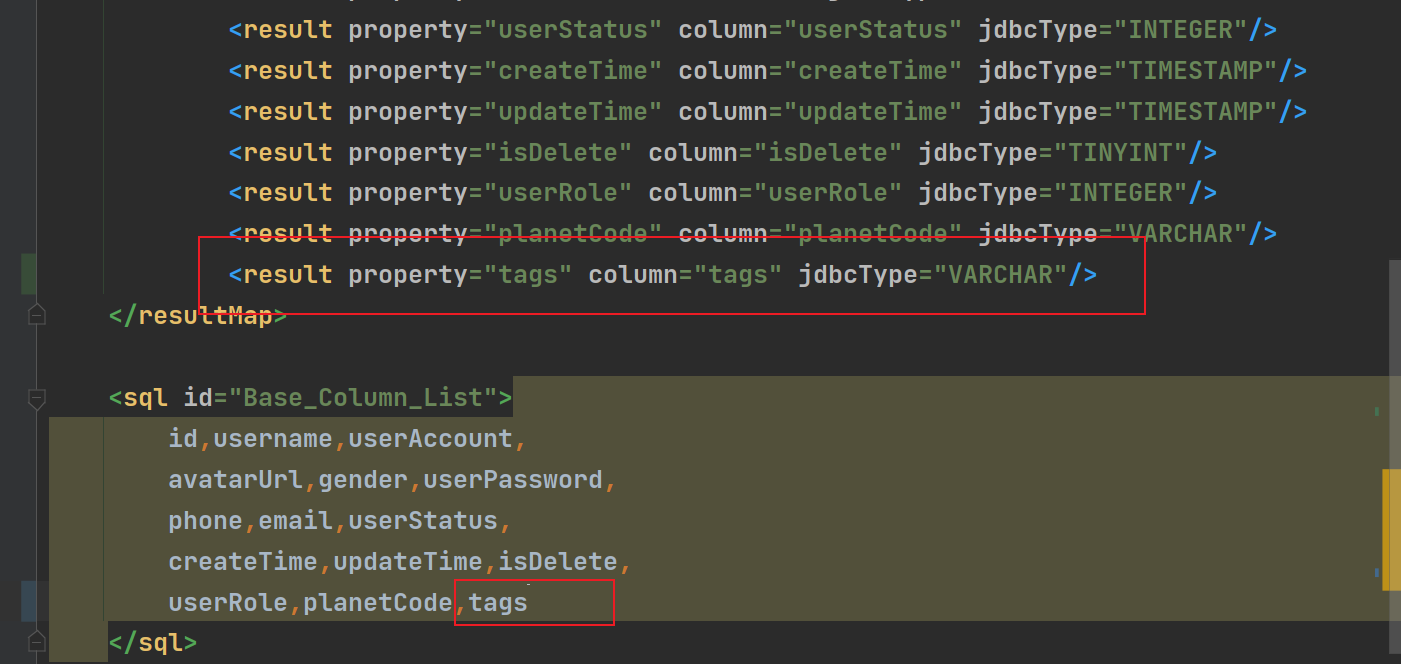
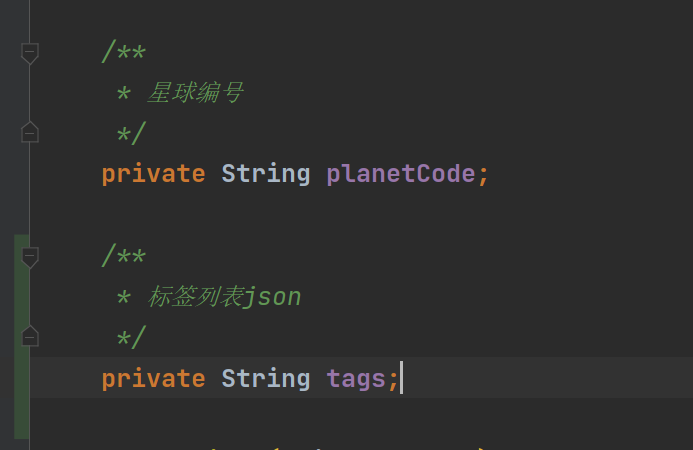
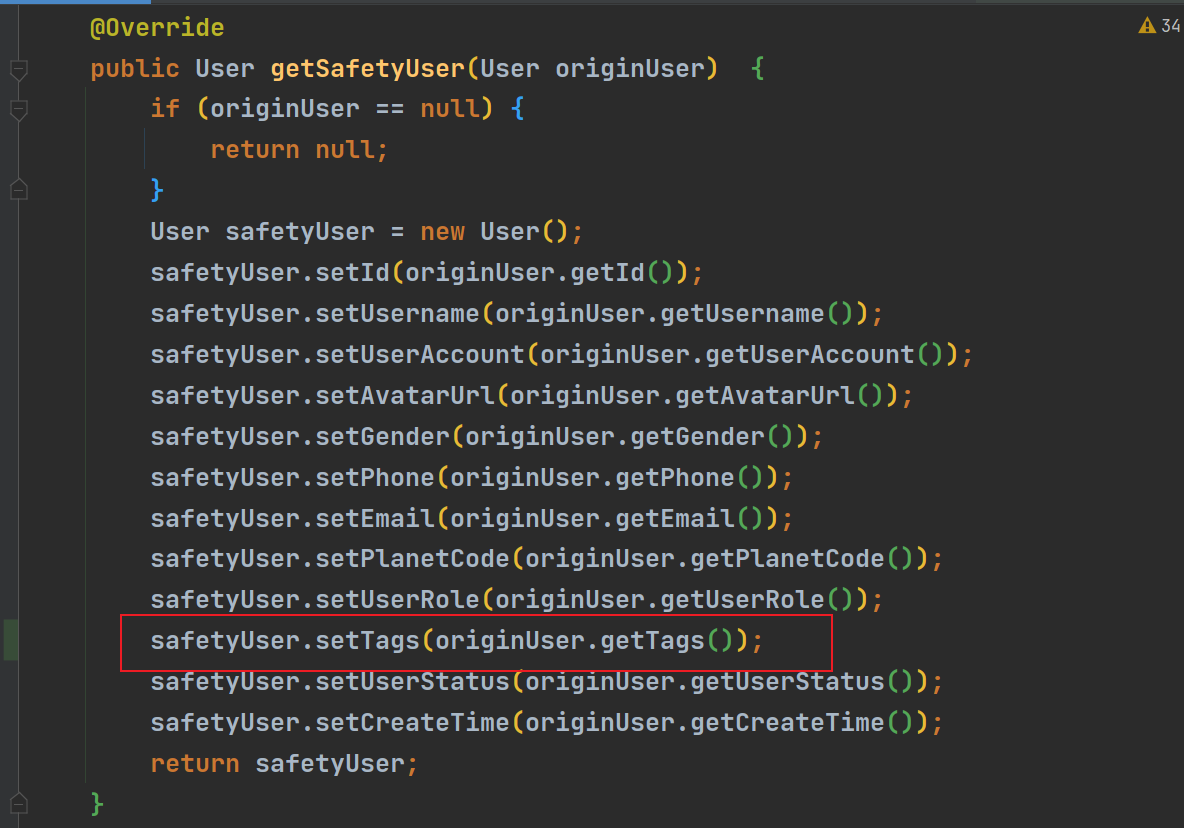 在表中插入tags的数据
在表中插入tags的数据 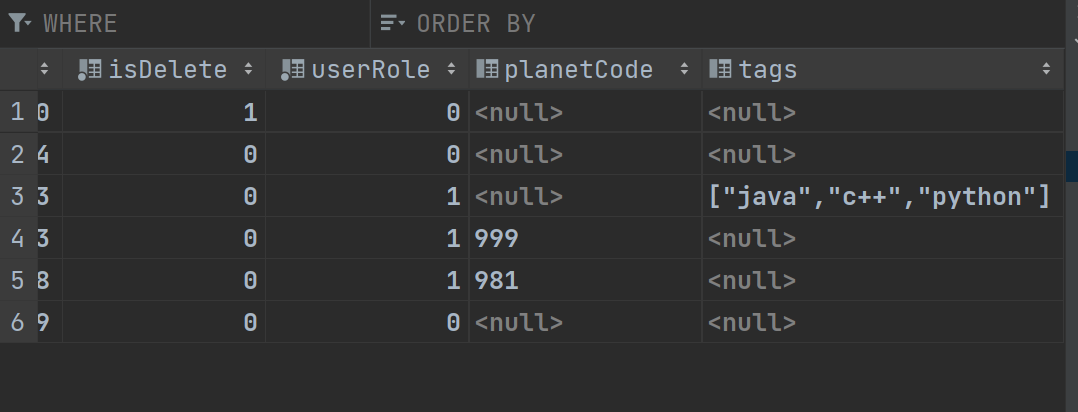 为了便于观察在配置文件中配置sql日志
为了便于观察在配置文件中配置sql日志  最后进行debug,打上断点
最后进行debug,打上断点  结果如下
结果如下  日志也生成了
日志也生成了
==> Preparing: SELECT id,username,userAccount,avatarUrl,gender,userPassword,phone,email,userStatus,createTime,updateTime,isDelete,userRole,planetCode,tags FROM user WHERE isDelete=0 AND (tags LIKE ? AND tags LIKE ?)
==> Parameters: %java%(String), %python%(String)
<== Columns: id, username, userAccount, avatarUrl, gender, userPassword, phone, email, userStatus, createTime, updateTime, isDelete, userRole, planetCode, tags
<== Row: 3, null, yupi, https://img1.baidu.com/it/u=1645832847,2375824523&fm=253&fmt=auto&app=138&f=JPEG?w=480&h=480, null, 12345678, null, null, 0, 2022-11-08 19:00:49, 2022-11-12 21:23:33, 0, 1, null, ["java","c++","python"]
<== Total: 1
Closing non transactional SqlSession [org.apache.ibatis.session.defaults.DefaultSqlSession@351e89fc]
2022-11-12 22:06:58.143 INFO 5196 --- [ionShutdownHook] com.zaxxer.hikari.HikariDataSource : HikariPool-1 - Shutdown initiated...
2022-11-12 22:06:58.172 INFO 5196 --- [ionShutdownHook] com.zaxxer.hikari.HikariDataSource : HikariPool-1 - Shutdown completed.
Disconnected from the target VM, address: '127.0.0.1:6638', transport: 'socket'注意踩坑点:由于是用户中心的代码,因为上线的原因,配置文件中的数据库是云服务器,现在测试的数据库是本地的,所以要根据自己的情况去修改配置,否则就会查询不出
4.第一种方法完成,现在进行第二种方法,在searchUsersByTags中修改代码
首先要引入gson依赖(反序列化)
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.8.9</version>
</dependency>第二种代码如下
@Override
public List<User> searchUsersByTags(List<String> tagNameList) {
if (CollectionUtils.isEmpty(tagNameList)) {
throw new BusinessException(ErrorCode.PARAMS_ERROR);
}
// //拼接 and 查询
// //like '%Java%' and like '%Python%'
// QueryWrapper<User> queryWrapper = new QueryWrapper<>();
// for(String tagName : tagNameList){
// queryWrapper=queryWrapper.like("tags",tagName);
// }
// List<User> userList = userMapper.selectList(queryWrapper);
// return userList.stream().map(this::getSafetyUser).collect(Collectors.toList());
//1.先查询所有用户
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
List<User> userList = userMapper.selectList(queryWrapper);
Gson gson = new Gson();
//2.在内存中判断是否包含要求的标签
return userList.stream().filter(user -> {
String tagsStr = user.getTags();
if (StringUtils.isBlank(tagsStr)) {
return false;
}
Set<String> tempTagNameSet = gson.fromJson(tagsStr, new TypeToken<Set<String>>() {
}.getType());
for (String tagName : tagNameList){
if (!tempTagNameSet.contains(tagName)){
return false;
}
}
return true;
}).map(this::getSafetyUser).collect(Collectors.toList());
}依照第一种方法进行测试,结果如下 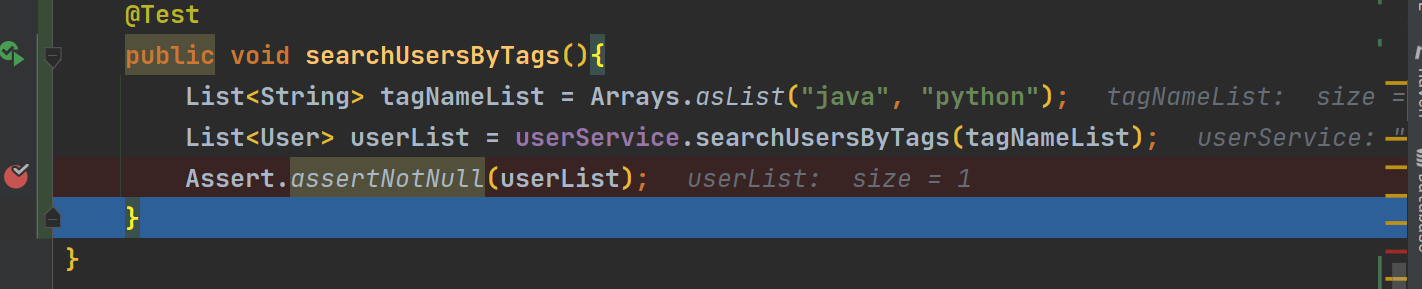
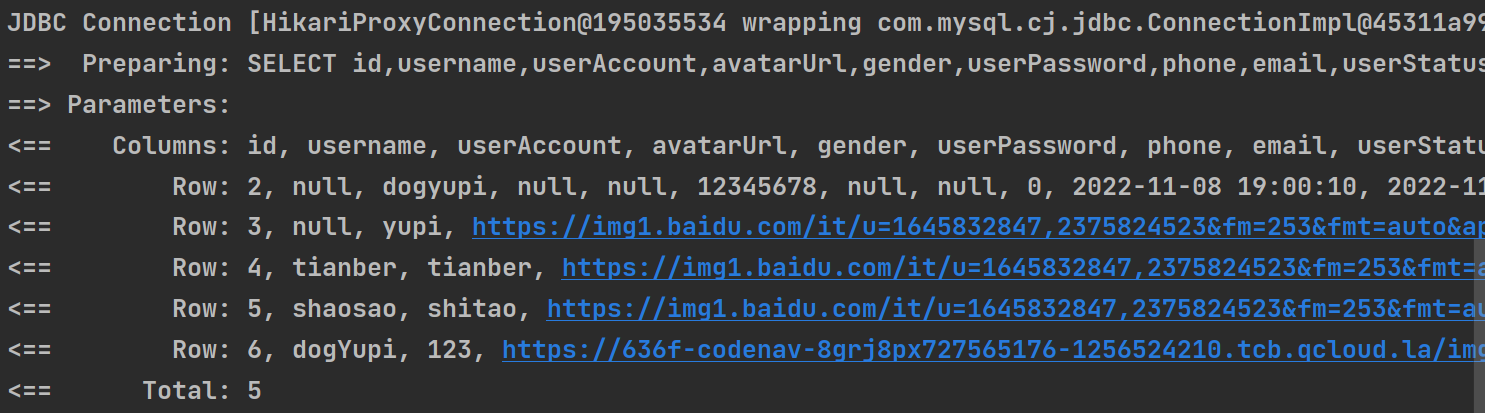
5.耗时的比较
继续修改searchUsersByTags的代码如下
@Override
public List<User> searchUsersByTags(List<String> tagNameList) {
if (CollectionUtils.isEmpty(tagNameList)) {
throw new BusinessException(ErrorCode.PARAMS_ERROR);
}
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
userMapper.selectCount(null);
long startTime = System.currentTimeMillis();
//拼接 and 查询
//like '%Java%' and like '%Python%'
for (String tagName : tagNameList) {
queryWrapper = queryWrapper.like("tags", tagName);
}
List<User> userList = userMapper.selectList(queryWrapper);
// return userList.stream().map(this::getSafetyUser).collect(Collectors.toList());
log.info("sql query time =" + (System.currentTimeMillis() - startTime));
//1.先查询所有用户
startTime = System.currentTimeMillis();
queryWrapper = new QueryWrapper<>();
userList = userMapper.selectList(queryWrapper);
Gson gson = new Gson();
//2.在内存中判断是否包含要求的标签
userList.stream().filter(user -> {
String tagsStr = user.getTags();
if (StringUtils.isBlank(tagsStr)) {
return false;
}
Set<String> tempTagNameSet = gson.fromJson(tagsStr, new TypeToken<Set<String>>() {
}.getType());
for (String tagName : tagNameList) {
if (!tempTagNameSet.contains(tagName)) {
return false;
}
}
return true;
}).map(this::getSafetyUser).collect(Collectors.toList());
log.info("menory query time =" + (System.currentTimeMillis() - startTime));
return userList;
}进行测试(这边就进行了两次): 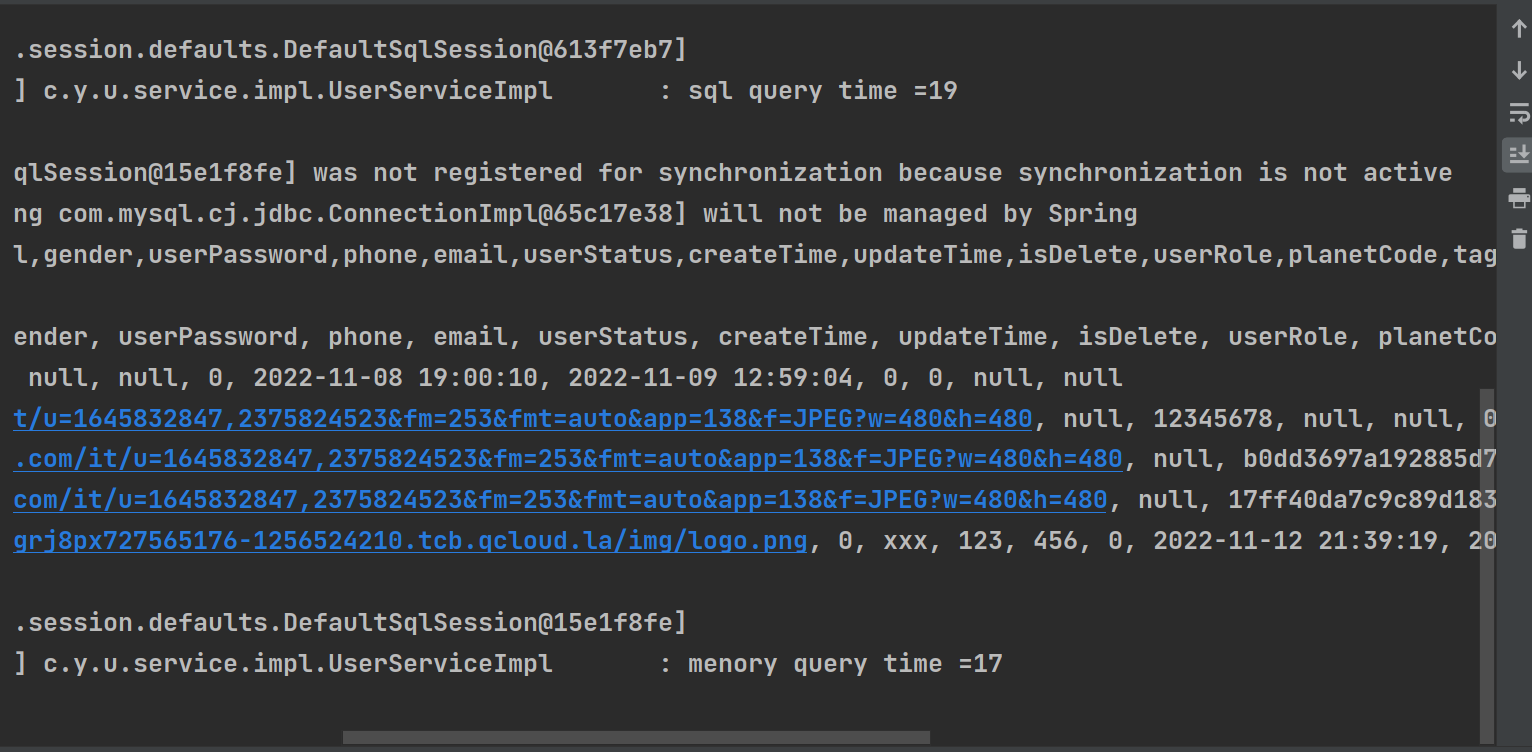
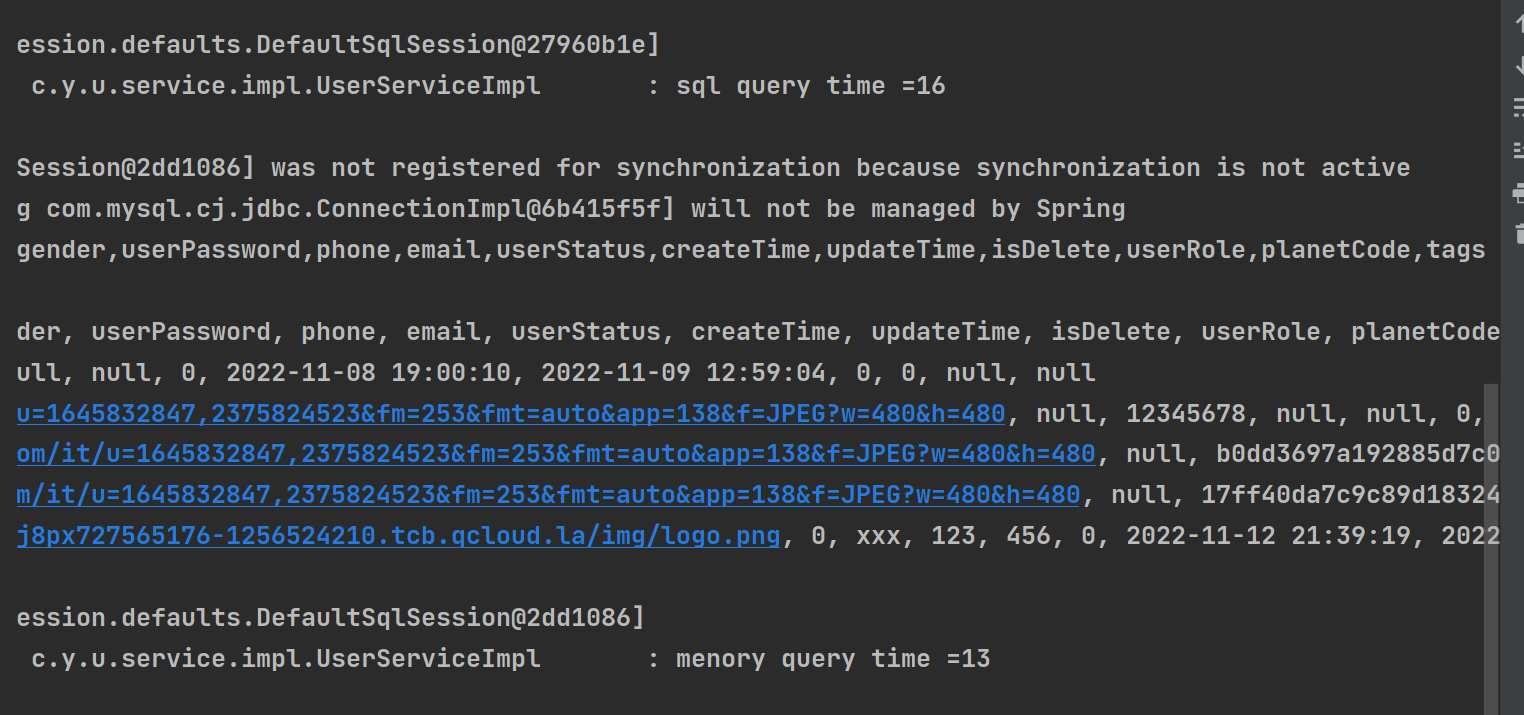 结论:我这边都是内存快,鱼皮是SQL的快,除去第一次链接数据库的时间,也还是内存快,可能和数据的数量有关,测试并不是很准确,尽量要在实际的应用场景中观察。
结论:我这边都是内存快,鱼皮是SQL的快,除去第一次链接数据库的时间,也还是内存快,可能和数据的数量有关,测试并不是很准确,尽量要在实际的应用场景中观察。



